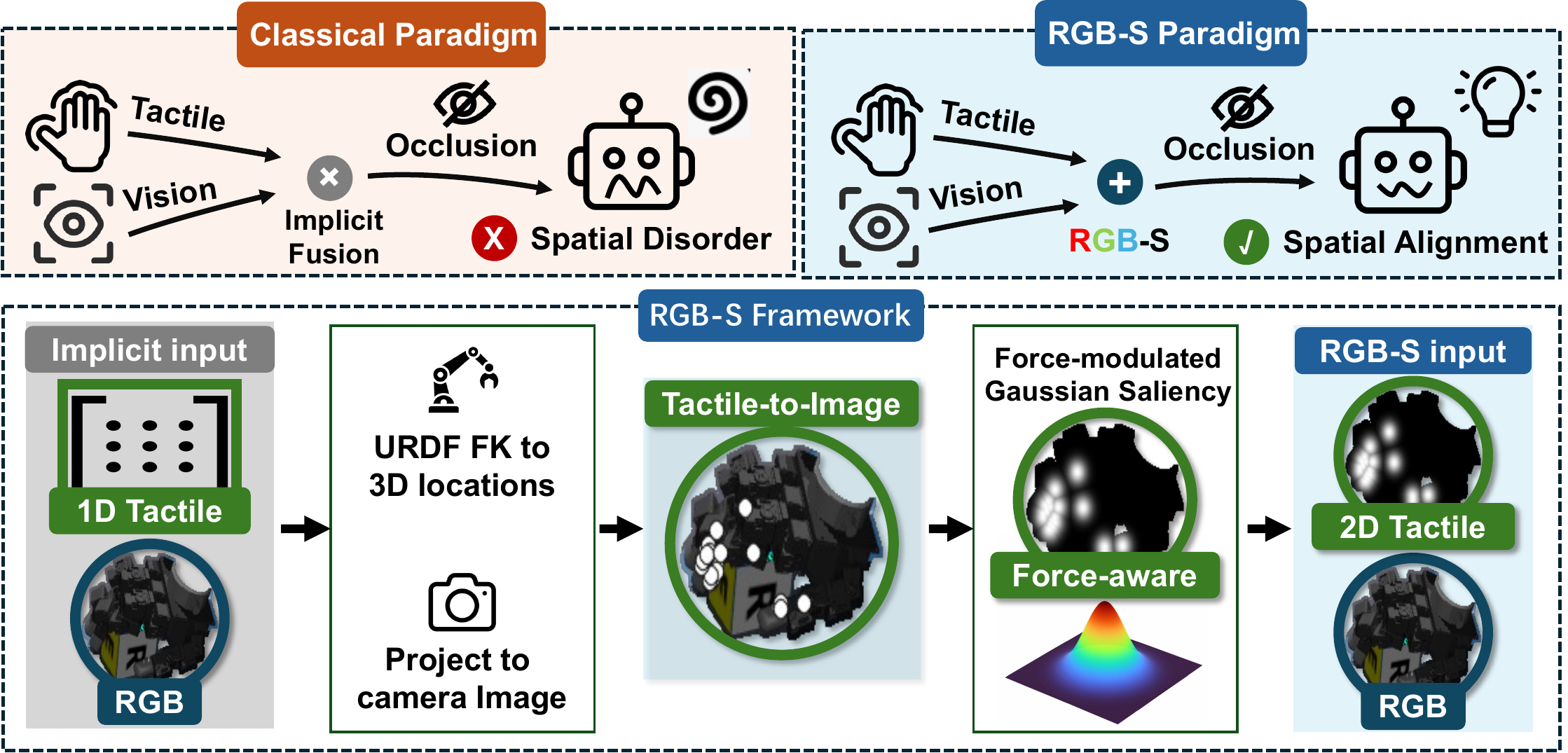
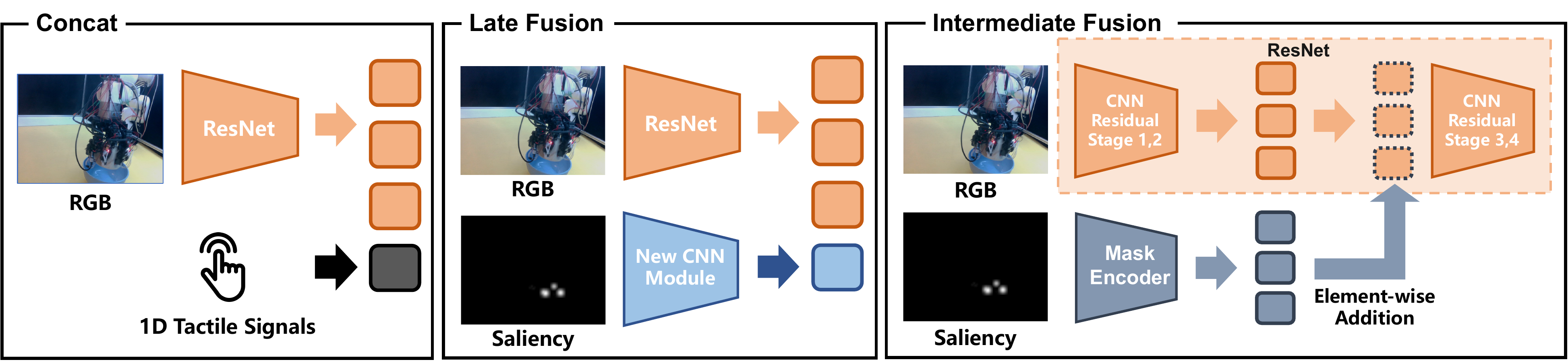
Effective visuo-tactile integration is critical for robotic dexterous manipulation, especially when visual observations are unreliable or occluded. However, robustly aligning sparse, heterogeneous tactile measurements with dense visual representations remains a fundamental challenge. Most existing approaches require policies to learn cross-modal correspondences implicitly from limited demonstrations, without leveraging geometric priors.
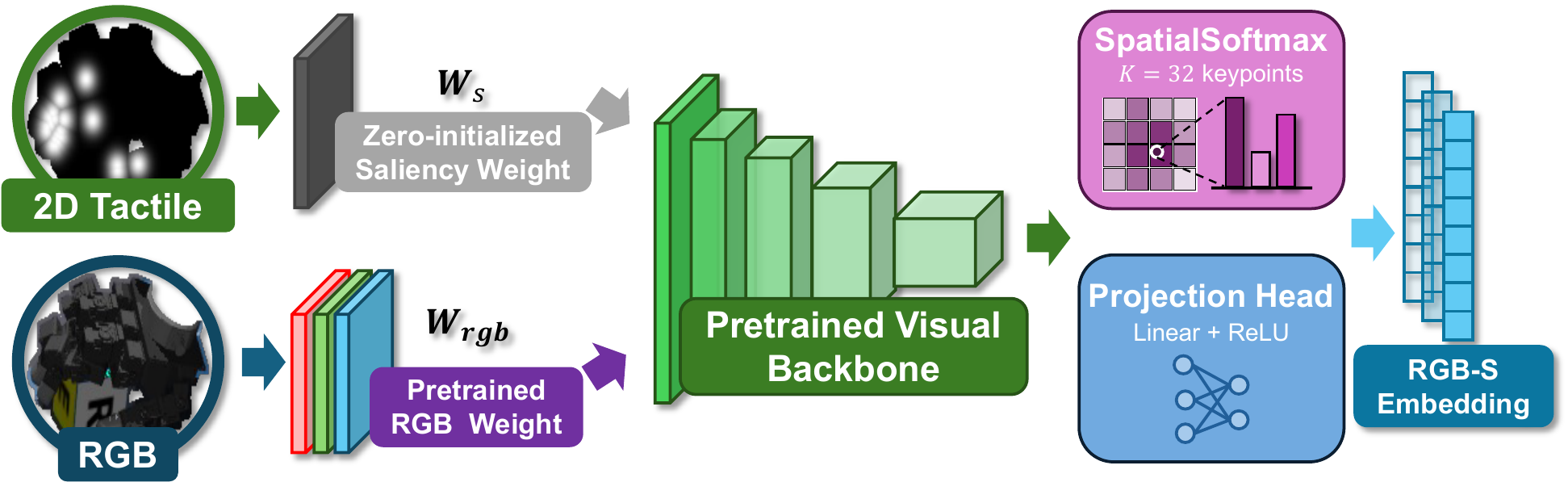
RGB-S explicitly grounds physical contacts in the image domain. Using robot forward kinematics and camera calibration, tactile sensor locations are projected onto the RGB image plane and rendered as force-modulated Gaussian saliency maps. These 2D spatial anchors are integrated through a zero-initialized conditioning architecture that preserves pretrained visual features while allowing the policy to learn from contact cues.
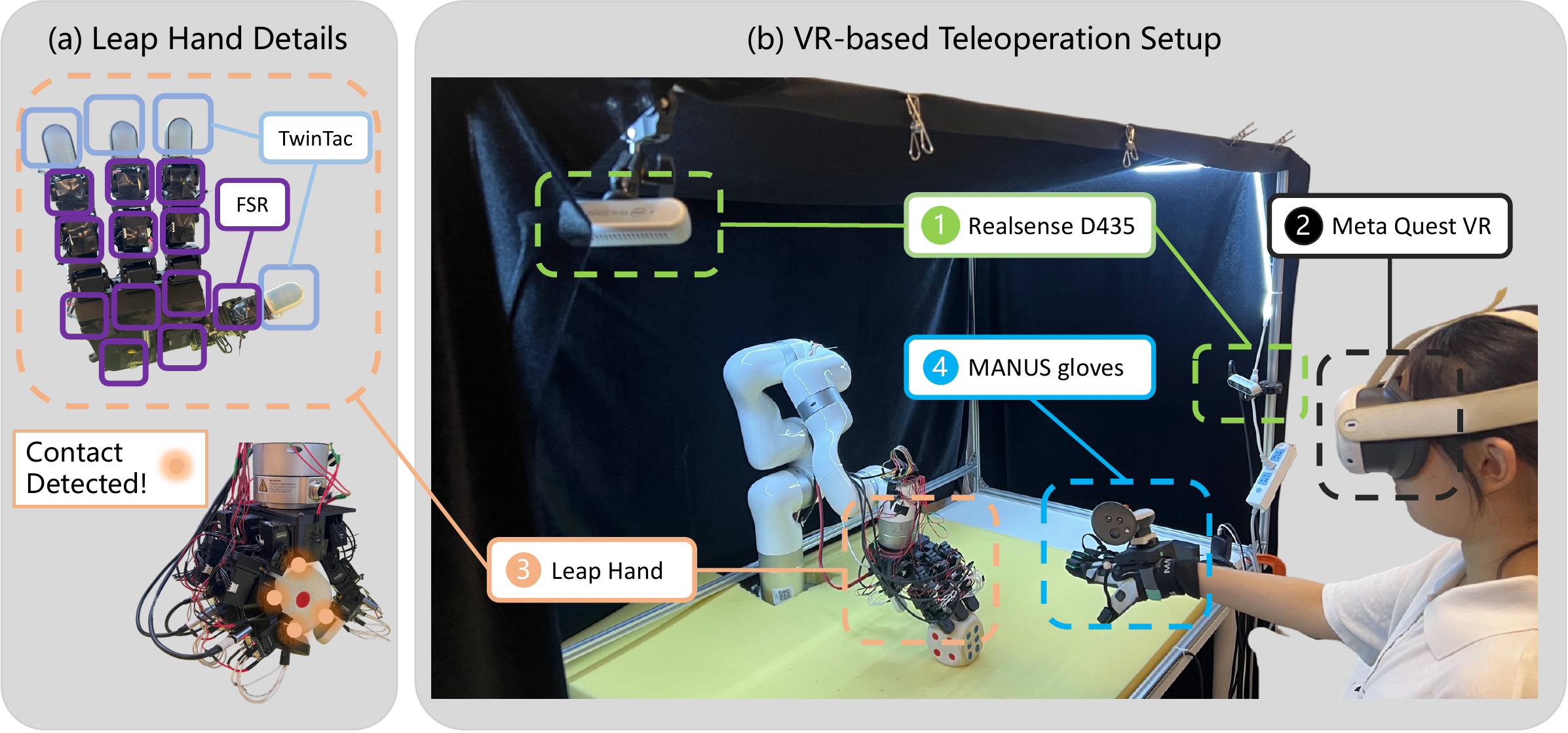
We evaluate RGB-S on six dexterous manipulation tasks in simulation and the real world under severe visual occlusions. Real-world experiments show that RGB-S improves occluded manipulation success rates by 26.7 percentage points over the strongest implicit visuo-tactile baseline.